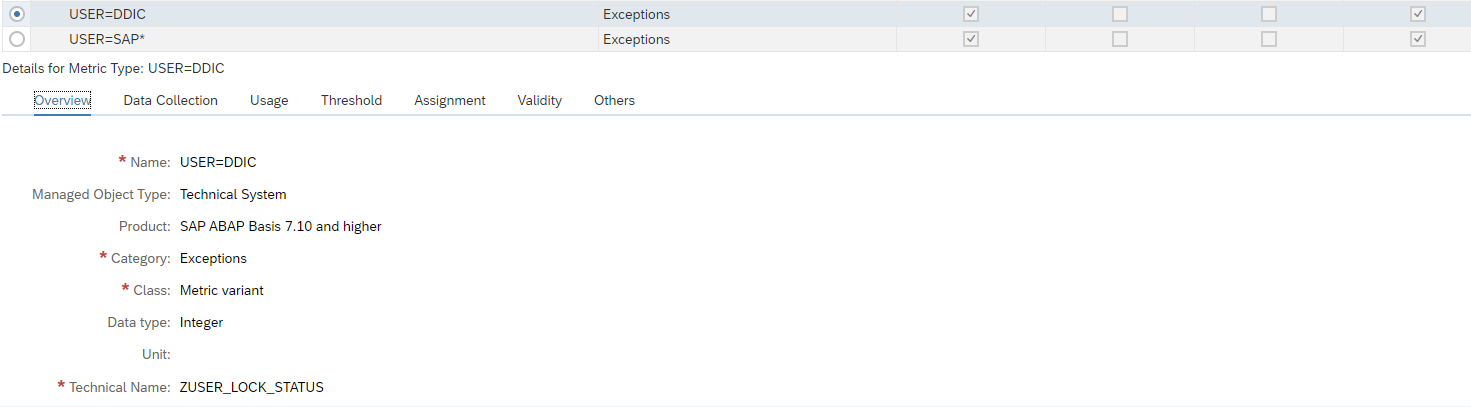
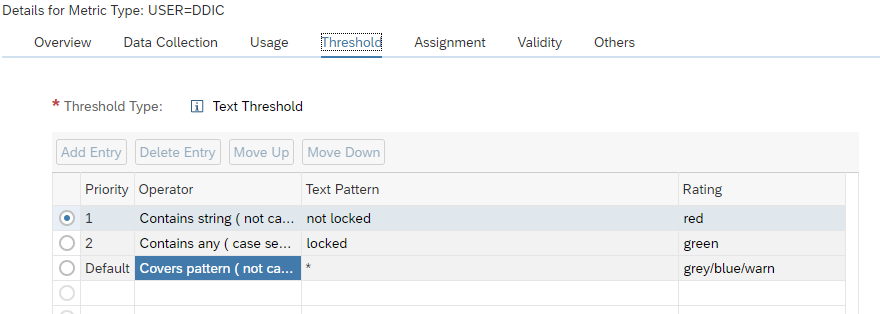
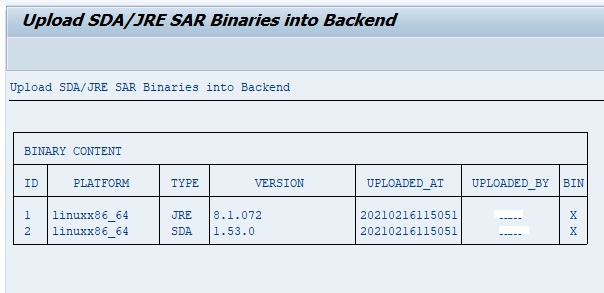
The alert management function is a central alert inbox function for SAP Focused Run. All alerts from all tools are coming together in the alert inbox.
Questions that will be answered in this blog are:
- Which alerts are sent to the Alert inbox?
- How to organize alert handling?
- How to execute alert review?
- How to reduce the amount of open alerts?
For practical use of the alert management function, read this dedicated blog.
Alert inbox
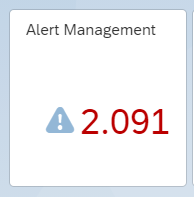
All alerts from all SAP Focused Run monitoring tools end up in the Alert Inbox:
This can be alerts from:
Don't let yourself be impressed by the high amount of alerts: this counter is across all tools and all systems, including non production. After some fine tuning of monitoring templates and thresholds, and clean up in the systems, this number will go down fast.
Alert handling
An alert is sent to the alert inbox. But for each alert you can configure as well if an alert is e-mailed, and/or send to external tool like ServiceNow.
The alert inbox has a scope filter just like all the other Focused Run tools. Use it to filter the alerts for you most important systems (most likely the productive systems, or even filter on the core S4HANA and/or ECC systems).
Depending on your organizational structure and amounts of systems, you need to agree on how you handle the alerts. Aspects to be taken care of:
- Prioritization of alerts; which ones go first? Solutions:
- Use filters for important systems
- First red alerts, then yellow alerts
- Fine tune alert thresholds to reduce invalid red alerts
- Assign processor or not: for larger teams do assign a processor to keep track
- Fill out comments for alerts that take longer to solve, so you track what has been done
- Consider to postpone alerts that require a change to get fixed (and the change takes a longer time to implement)
- Using the SLA functions or not?
- Who is allowed to confirm an alert?
Alert review
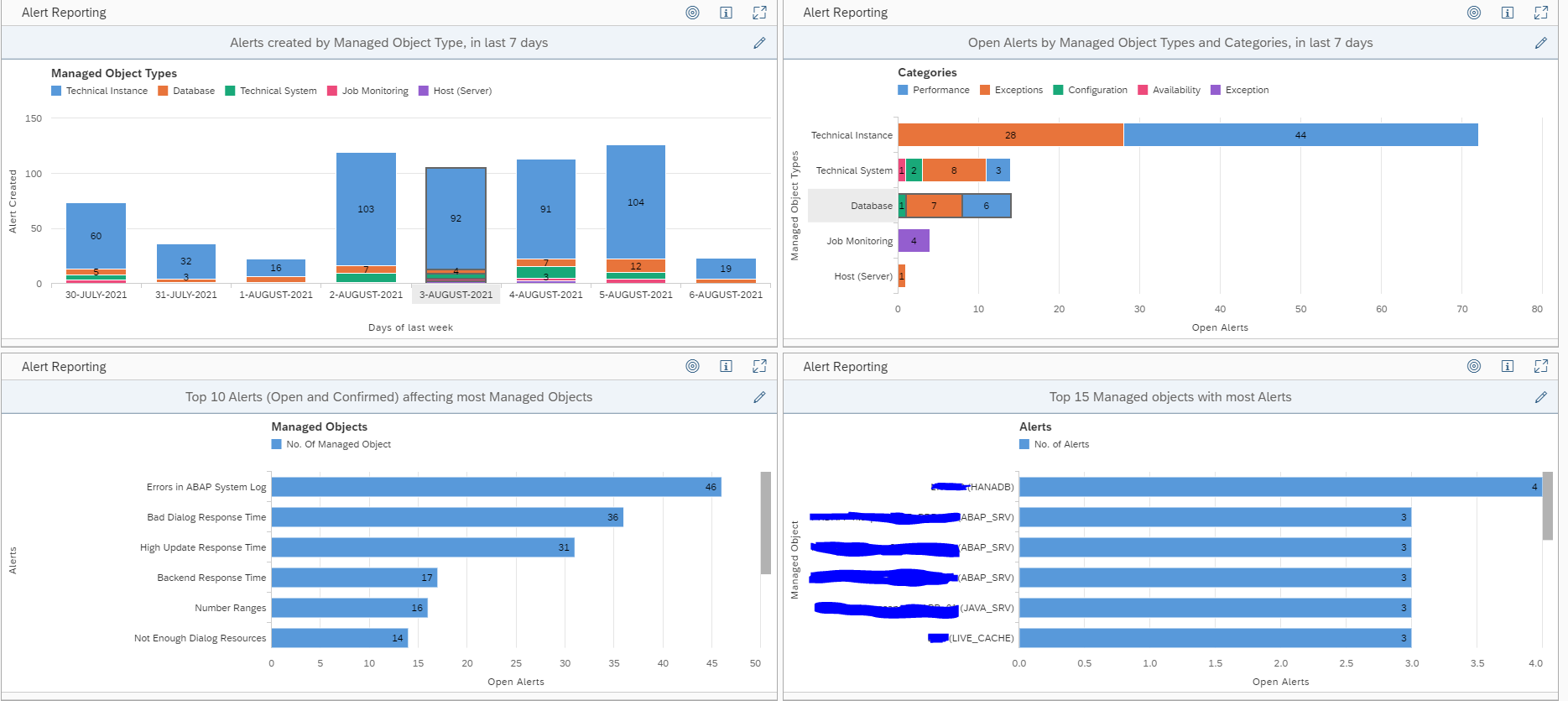
You can use the initial alert dashboard, or the alert reporting overview, or create your own dashboards:
The overview shows the open alerts:
At the start of your SAP Focused Run implementation you should at least weekly review this. It gives you insights into:
- The type of alerts most frequently popping up
- The systems that generate the most alerts
- The average time an alert is open
When you are getting more mature and used to solving the issues and alerts, you can reduce the alert review frequency to for example monthly.
Open alert reduction
To reduce the open alerts consider this sequence:
- Solve the issues in the systems: clean up, apply permanent solutions
- Fine tune the metric thresholds for false alerts, and classify not so important alerts as yellow: keep red for the important alerts
- Work on the resolution time: also here, focus on the red alerts which are important
Bad practices (often deployed by KPI drive service providers):
- Increase thresholds, without clean up or without solving the issues permanently
- Simply close each repetitive alert fast without checking and solving the root cause for repetitive failure
- Only look at subsection of the alerts
- Don’t look at self monitoring items (without solving self monitoring issues)
- Blame Focused Run for having bugs (without looking for OSS notes and without reporting issues)
- Don’t confirm the alerts (so they keep open and don’t send new mails, or don’t create new ServiceNow tickets)
If you are confronted with such a service provider, use the alerting reporting tools also for the closed alerts to find evidences of such behaviors.
Missed alerts
After incidents you have (mainly in your productive system), check if Focused Run generated the proper alert or not.
Cases that can happen:
- Focused Run did alert the situation, but it was not picked up fast enough by the processors: organizational measures, or consider the mail sending option
- Focused Run did measure the situation, but the alert was not configured (for example batch job alert was not set)
- Focused Run did measure the situation, but the threshold was not reached: lower the threshold in the template
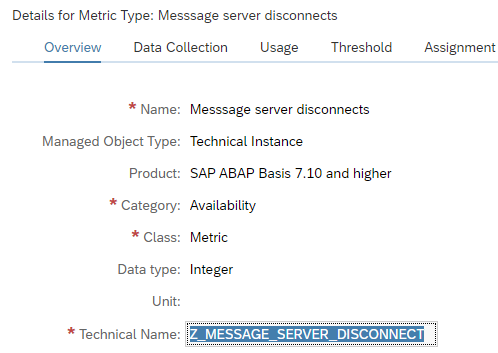
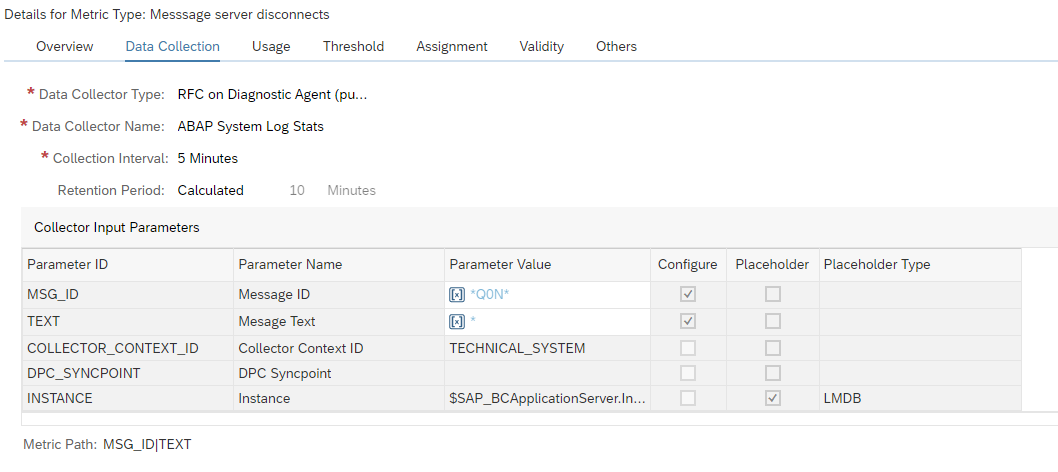
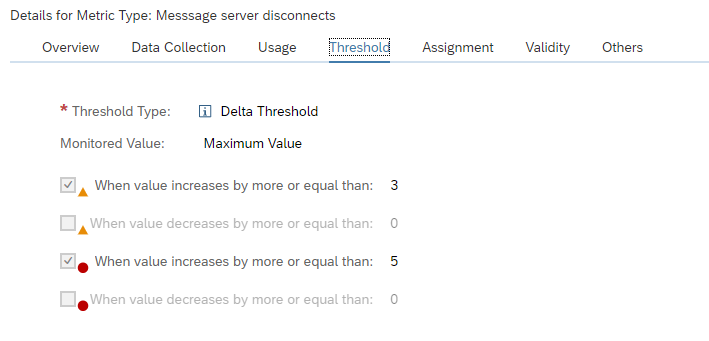
- Focused Run did measure the situation, but it was not specific enough. This can happen with SM21 system messages. Consider creation of very specific custom metrics for specific messages (for example for application server connectivity loss to database).
- Focused Run did not measure the situation: check if you can activate an out-of-the-box monitoring item for the situation. Not all measurements are active in the templates by default. If no out-of-the box exists, consider creating a custom metric. Or check if you can monitor side-effects of occurring bad situations.
The goal of this analysis is to keep improving the alerting accuracy: alerts should not be missed and valid (not false).